GFS分布式文件存儲系統(tǒng) 理論與信息系統(tǒng)運行維護(hù)服務(wù)實踐
引言:分布式文件存儲的必要性
在當(dāng)今大數(shù)據(jù)與云計算時代,傳統(tǒng)的集中式文件存儲服務(wù)器在處理海量數(shù)據(jù)、高并發(fā)訪問及高可用性需求時,已顯得力不從心。Google文件系統(tǒng)(Google File System,簡稱GFS)作為一種開創(chuàng)性的分布式文件存儲系統(tǒng),為大規(guī)模數(shù)據(jù)密集型應(yīng)用提供了堅實的存儲基礎(chǔ)。本文將探討GFS的理論架構(gòu),并闡述其在信息系統(tǒng)運行維護(hù)服務(wù)中的實踐應(yīng)用。
第一部分:GFS的理論架構(gòu)解析
GFS的核心設(shè)計目標(biāo)是處理大規(guī)模、高吞吐量的數(shù)據(jù)訪問,尤其適用于搜索引擎等需要處理海量非結(jié)構(gòu)化數(shù)據(jù)的應(yīng)用場景。其理論架構(gòu)主要圍繞以下幾個關(guān)鍵理念構(gòu)建:
- 系統(tǒng)假設(shè)與設(shè)計原則:GFS建立在“硬件故障是常態(tài)而非例外”的假設(shè)之上,因此系統(tǒng)設(shè)計首要考慮容錯性。它通過廉價的商用硬件構(gòu)建集群,利用軟件層面的冗余機(jī)制來確保數(shù)據(jù)的可靠性與系統(tǒng)的持續(xù)可用性。其核心設(shè)計原則包括:支持大文件(如數(shù)百GB)、以追加寫(append)為主(而非隨機(jī)寫)的工作負(fù)載優(yōu)化、以及高并發(fā)讀取的高吞吐量。
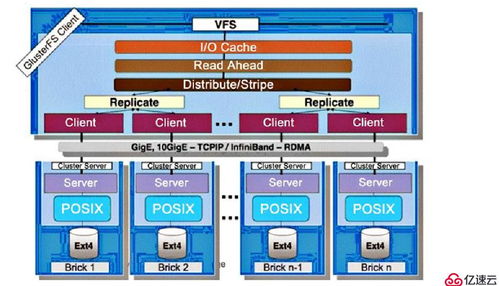
- 核心組件與架構(gòu):一個GFS集群主要由三類節(jié)點組成:
- 主服務(wù)器(Master):負(fù)責(zé)管理整個文件系統(tǒng)的元數(shù)據(jù)(如命名空間、訪問控制信息、文件到數(shù)據(jù)塊的映射等),協(xié)調(diào)數(shù)據(jù)塊租約、垃圾回收及數(shù)據(jù)塊遷移。Master是系統(tǒng)的“大腦”,但其設(shè)計力求簡潔,將數(shù)據(jù)流的管理下放。
- 數(shù)據(jù)塊服務(wù)器(Chunkserver):負(fù)責(zé)實際存儲數(shù)據(jù)。文件被分割成固定大小(如64MB)的數(shù)據(jù)塊,每個數(shù)據(jù)塊在多個Chunkserver上復(fù)制(通常為3份),以實現(xiàn)容錯。數(shù)據(jù)讀寫操作直接在客戶端和Chunkserver之間進(jìn)行,避免了主服務(wù)器的瓶頸。
- 客戶端(Client):與應(yīng)用程序鏈接的庫,遵循GFS協(xié)議與Master和Chunkserver交互,為應(yīng)用程序提供文件系統(tǒng)API。
- 關(guān)鍵工作流程:
- 寫操作:客戶端從Master獲取目標(biāo)數(shù)據(jù)塊的主副本位置,然后將數(shù)據(jù)推送到所有副本。主副本負(fù)責(zé)確定所有副本的寫入順序,確保數(shù)據(jù)一致性。這種“數(shù)據(jù)流與控制流分離”的模式,有效提升了寫入效率。
- 讀操作:客戶端從Master獲取數(shù)據(jù)塊副本的位置信息,然后選擇最近的副本直接讀取數(shù)據(jù)。
- 容錯與一致性:通過多副本機(jī)制實現(xiàn)高可用。Master通過心跳機(jī)制監(jiān)控Chunkserver狀態(tài),并在副本失效時啟動復(fù)制。GFS提供一種寬松的一致性模型,通過記錄追加(record append)操作保證數(shù)據(jù)的“至少一次”原子寫入,非常適合其目標(biāo)應(yīng)用場景。
第二部分:作為信息系統(tǒng)運行維護(hù)服務(wù)的基礎(chǔ)設(shè)施
將GFS或類似分布式文件系統(tǒng)(如HDFS,其靈感源于GFS)部署為企業(yè)信息系統(tǒng)的一部分,對運行維護(hù)服務(wù)提出了新的要求和機(jī)遇。
- 運維服務(wù)的新維度:
- 大規(guī)模集群管理:運維團(tuán)隊需要管理成百上千臺服務(wù)器組成的集群,包括硬件監(jiān)控、操作系統(tǒng)部署、網(wǎng)絡(luò)配置等。自動化運維工具(如Ansible, Puppet)和監(jiān)控系統(tǒng)(如Prometheus, Grafana)變得至關(guān)重要。
- 數(shù)據(jù)可靠性與備份:雖然多副本提供了硬件級的容錯,但運維仍需關(guān)注跨機(jī)架、跨數(shù)據(jù)中心的副本放置策略,以防范機(jī)架或數(shù)據(jù)中心級故障。仍需制定針對邏輯錯誤或災(zāi)難的額外備份與恢復(fù)策略。
- 性能監(jiān)控與調(diào)優(yōu):需要持續(xù)監(jiān)控Master負(fù)載、Chunkserver磁盤I/O、網(wǎng)絡(luò)帶寬、數(shù)據(jù)塊分布均衡性等關(guān)鍵指標(biāo),及時進(jìn)行擴(kuò)容、負(fù)載均衡或參數(shù)調(diào)優(yōu)。
- 故障處理與高可用保障:
- Master高可用:原版GFS中Master是單點,現(xiàn)代實踐中通常通過主備(如HDFS的NameNode HA)或基于Paxos/Raft協(xié)議的多主方案來消除這一單點故障。運維需確保故障切換(Failover)流程的可靠與快速。
- 日常故障響應(yīng):Chunkserver故障、磁盤損壞、網(wǎng)絡(luò)分區(qū)是常態(tài)。運維體系需要能自動檢測、報告并盡可能自動修復(fù)(如重新復(fù)制數(shù)據(jù)塊)。
- 容量規(guī)劃與成本控制:運維服務(wù)需根據(jù)業(yè)務(wù)增長預(yù)測存儲需求,進(jìn)行科學(xué)的容量規(guī)劃。在保證性能與可靠性的前提下,通過數(shù)據(jù)壓縮、歸檔冷數(shù)據(jù)、優(yōu)化副本因子(如對不重要數(shù)據(jù)降低副本數(shù))等方式控制存儲成本。
- 安全與訪問控制:在分布式環(huán)境中,需強(qiáng)化網(wǎng)絡(luò)訪問控制、認(rèn)證與授權(quán)機(jī)制,防止未授權(quán)訪問。運維需定期進(jìn)行安全審計和漏洞掃描。
第三部分:挑戰(zhàn)與最佳實踐
- 挑戰(zhàn):系統(tǒng)復(fù)雜性高,調(diào)試?yán)щy;對小文件存儲效率相對較低(元數(shù)據(jù)壓力大);強(qiáng)一致性場景支持有限。
- 最佳實踐:
- 自動化先行:將所有部署、配置、擴(kuò)縮容操作自動化。
- 監(jiān)控驅(qū)動運維:建立全方位的監(jiān)控和告警體系,實現(xiàn)從基礎(chǔ)設(shè)施到應(yīng)用層的可觀測性。
- 變更管理:任何對生產(chǎn)集群的變更(如軟件升級、配置修改)都必須經(jīng)過嚴(yán)格的測試和灰度發(fā)布流程。
- 文檔與知識沉淀:詳細(xì)記錄集群架構(gòu)、運維手冊和故障處理案例,形成團(tuán)隊知識庫。
- 與上層應(yīng)用協(xié)同:引導(dǎo)應(yīng)用開發(fā)者遵循GFS的最佳使用模式(如寫入大文件、順序/追加讀寫),以最大化系統(tǒng)效益。
結(jié)論
GFS分布式文件存儲系統(tǒng)以其獨特的設(shè)計哲學(xué),解決了海量數(shù)據(jù)存儲的根本性難題,成為現(xiàn)代大型信息系統(tǒng)不可或缺的基石。對于信息系統(tǒng)運行維護(hù)服務(wù)而言,管理好這樣一個分布式存儲基礎(chǔ)設(shè)施,意味著從傳統(tǒng)的單機(jī)/小型集群運維,向自動化、智能化、面向大規(guī)模集群的SRE(站點可靠性工程)模式演進(jìn)。深入理解GFS的理論,并將其與扎實的運維實踐相結(jié)合,是保障數(shù)據(jù)持續(xù)可靠、服務(wù)穩(wěn)定高效的關(guān)鍵。隨著技術(shù)的發(fā)展,雖然出現(xiàn)了對象存儲、NewSQL數(shù)據(jù)庫等更多存儲范式,但GFS所奠定的思想,仍在持續(xù)影響著整個分布式計算領(lǐng)域。
如若轉(zhuǎn)載,請注明出處:http://m.tbxjxa.cn/product/70.html
更新時間:2026-04-08 20:36:15